1. Introduction
In this article, we are going to present a custom XLSX parser based on Java annotations. The application will be using the Apache POI library to read the structure of the Excel file and then map all entries into the POJO object.
2. Setup project
The project will use several dependencies from apache-poi. We also used Lombok to generate common methods for POJO classes like setters, getters, and constructors.
The pom.xml file will contain the following items:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>libraries</artifactId>
<groupId>com.frontbackend.libraries</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>apache-poi</artifactId>
<properties>
<lombok.version>1.16.22</lombok.version>
<apache.poi.version>3.17</apache.poi.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>${apache.poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${apache.poi.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
The latest versions of used libraries could be found in our Maven Repository:
3. Project structure
The project is organized in the following structure:
├── pom.xml
├── src
│ ├── main
│ │ ├── java
│ │ │ └── com
│ │ │ └── frontbackend
│ │ │ └── libraries
│ │ │ └── apachepoi
│ │ │ ├── MainParseXLSXUsingAnnotations.java
│ │ │ ├── model
│ │ │ │ └── Post.java
│ │ │ └── parser
│ │ │ ├── XLSXField.java
│ │ │ ├── XLSXHeader.java
│ │ │ └── XLSXParser.java
│ │ └── resources
│ │ └── posts.xlsx
4. XLSX Parser classes
We can distinguish three classes responsible for processing XLSX files:
XLSXField- custom annotation used to mark field in POJO class and connect it with the column from XLSX document,XLSXHeader- is a wrapper class used to hold information about fields, columns, and columns positions in the Excel file,XLSXParser- the main class responsible for parsing XLSX files and set values into POJO objects.
Starting with the XLSXField - which is an annotation used to connect column with a field in Java class:
package com.frontbackend.libraries.apachepoi.parser;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface XLSXField {
String column() default "";
}
The XLSXHeader is a helper class that wraps data like class field name, column name from XLSX file, and column index:
package com.frontbackend.libraries.apachepoi.parser;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.ToString;
@AllArgsConstructor
@Getter
@ToString
public class XLSXHeader {
private final String fieldName;
private final String xlsxColumnName;
private final int columnIndex;
}
And finally the base utility class responsible for parsing Excel files - XLSXParser:
package com.frontbackend.libraries.apachepoi.parser;
import java.io.InputStream;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellType;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class XLSXParser<T> {
private static final int HEADER_ROW_INDEX = 0;
private static final int SHEET_INDEX = 0;
public List<T> parse(InputStream inputStream, Class<T> cls) throws Exception {
List<T> out = new ArrayList<>();
XSSFWorkbook workbook = new XSSFWorkbook(inputStream);
Sheet sheet = workbook.getSheetAt(SHEET_INDEX);
List<XLSXHeader> xlsxHeaders = modelObjectToXLSXHeader(cls, sheet);
for (Row row : sheet) {
if (row.getRowNum() > HEADER_ROW_INDEX) {
out.add(createRowObject(xlsxHeaders, row, cls));
}
}
return out;
}
private T createRowObject(List<XLSXHeader> xlsxHeaders, Row row, Class<T> cls) throws Exception {
T obj = cls.newInstance();
Method[] declaredMethods = obj.getClass()
.getDeclaredMethods();
for (XLSXHeader xlsxHeader : xlsxHeaders) {
Cell cell = row.getCell(xlsxHeader.getColumnIndex());
String field = xlsxHeader.getFieldName();
Optional<Method> setter = Arrays.stream(declaredMethods)
.filter(method -> isSetterMethod(field, method))
.findFirst();
if (setter.isPresent()) {
Method setMethod = setter.get();
setMethod.invoke(obj, cell.getStringCellValue());
}
}
return obj;
}
private boolean isSetterMethod(String field, Method method) {
return method.getName()
.equals("set" + field.substring(0, 1)
.toUpperCase()
+ field.substring(1));
}
private List<XLSXHeader> modelObjectToXLSXHeader(Class<T> cls, Sheet sheet) {
return Stream.of(cls.getDeclaredFields())
.filter(field -> field.getAnnotation(XLSXField.class) != null)
.map(field -> {
XLSXField importField = field.getAnnotation(XLSXField.class);
String xlsxColumn = importField.column();
int columnIndex = findColumnIndex(xlsxColumn, sheet);
return new XLSXHeader(field.getName(), xlsxColumn, columnIndex);
})
.collect(Collectors.toList());
}
private int findColumnIndex(String columnTitle, Sheet sheet) {
Row row = sheet.getRow(HEADER_ROW_INDEX);
if (row != null) {
for (Cell cell : row) {
if (CellType.STRING.equals(cell.getCellTypeEnum()) && columnTitle.equals(cell.getStringCellValue())) {
return cell.getColumnIndex();
}
}
}
return 0;
}
}
Note that for the sake of simplicity we assume that the first row in an Excel file will be our table header, and also the first sheet will contain all the data:
private static final int HEADER_ROW_INDEX = 0;
private static final int SHEET_INDEX = 0;
The parse(...) method is responsible for reading XLSX documents using the Apache POI library and parsing values from it into a specific Java model instance.
In the first step, we create a list of helper classes that contains all the necessary information like field name, related column, and column index:
List<XLSXHeader> xlsxHeaders = modelObjectToXLSXHeader(cls, sheet);
In modelObjectToXLSXHeader() method we iterate over all declared in specified class fields and filter all marked with XLSXField annotation. Then we are searching for a column in an Excel file with the same name as provided in the annotation column property. The method returns the list of wrapped objects XLSXHeader.
private List<XLSXHeader> modelObjectToXLSXHeader(Class<T> cls, Sheet sheet) {
return Stream.of(cls.getDeclaredFields())
.filter(field -> field.getAnnotation(XLSXField.class) != null)
.map(field -> {
XLSXField importField = field.getAnnotation(XLSXField.class);
String xlsxColumn = importField.column();
int columnIndex = findColumnIndex(xlsxColumn, sheet);
return new XLSXHeader(field.getName(), xlsxColumn, columnIndex);
})
.collect(Collectors.toList());
}
The createRowObject() method creates an instance of a specified POJO object and filled the fields with values according to the data from the XLSX file.
As a result parse() method returns a list of POJO objects.
5. Run and test a sample program
In order to test the implementation of the XLSX parser, we created a simple object with three fields marked with @XLSXField annotation:
package com.frontbackend.libraries.apachepoi.model;
import com.frontbackend.libraries.apachepoi.parser.XLSXField;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
@Setter
@Getter
@ToString
public class Post {
@XLSXField(column = "Title")
private String title;
@XLSXField(column = "Content")
private String content;
@XLSXField(column = "URL")
private String url;
}
Fields will be related with the following column from the Excel file:
| Field | Column |
| title | Title |
| content | Content |
| url | URL |
Our sample XLSX file with have the following structure:
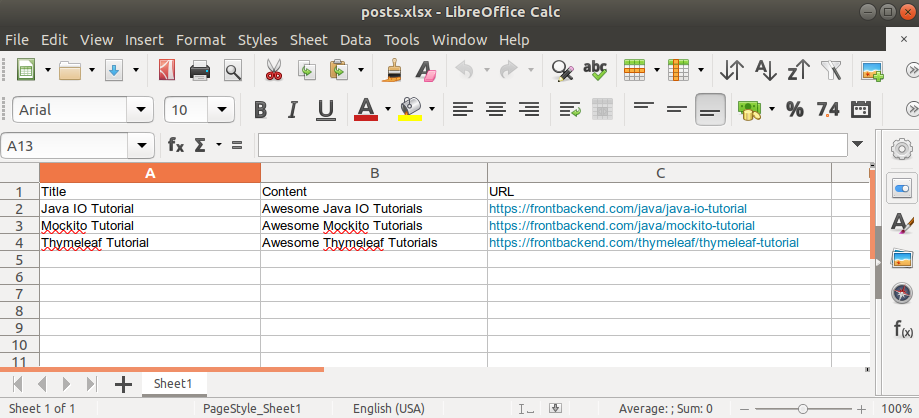
The sample Java program that will parse the posts.xlsx file located in the project resource folder looks as follows:
package com.frontbackend.libraries.apachepoi;
import java.io.InputStream;
import java.util.List;
import com.frontbackend.libraries.apachepoi.model.Post;
import com.frontbackend.libraries.apachepoi.parser.XLSXParser;
public class MainParseXLSXUsingAnnotations {
public static void main(String[] args) {
XLSXParser<Post> postsXLSXParser = new XLSXParser<>();
InputStream xlsxFile = postsXLSXParser.getClass()
.getClassLoader()
.getResourceAsStream("posts.xlsx");
try {
List<Post> list = postsXLSXParser.parse(xlsxFile, Post.class);
System.out.println(list);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Here:
- first, we created an instance of
XLSXParserdedicated for thePostclass, - in the next step we retrieved data from the
posts.xlsxfile, - then file stream is used to parse the file using the
XLSXParser.parse(...)method.
As a result, we have a list of three POJO instances that correspond to the rows in the Excel document:
[Post(title=Java IO Tutorial, content=Awesome Java IO Tutorials, url=https://frontbackend.com/java/java-io-tutorial),
Post(title=Mockito Tutorial, content=Awesome Mockito Tutorials, url=https://frontbackend.com/java/mockito-tutorial),
Post(title=Thymeleaf Tutorial, content=Awesome Thymeleaf Tutorials, url=https://frontbackend.com/thymeleaf/thymeleaf-tutorial)]
6. Conclusion
In this article, we presented how to create an XLSX parser based on annotations in Java using the Apache POI library. Note that we showed a simple example of an Excel file, also we convert all values into strings, but it a good point to start some more complex functionality.
As always the code used in this article is available in our GitHub repository.
{{ 'Comments (%count%)' | trans {count:count} }}
{{ 'Comments are closed.' | trans }}